Der Einsatz von Hochverfügbarkeitslösungen (High Availability) ist heutzutage ein wichtiges Element von auf maximale Zuverlässigkeit ausgelegten Infrastrukturen. Auch für das IT-Monitoring-Werkzeug OpenNMS können derartige Lösungen eingerichtet werden. Allerdings gibt es hier keine optimale Lösung – je nachdem, welche Prioritäten bei einer HA-Lösung gesetzt werden, sieht die passende Lösung anders aus und hat ihre Vor- und Nachteile. Im Folgenden werden einige Möglichkeiten gezeigt.
Active-Active
Vorteil:
Kein Datenverlust, schneller Wechsel vom produktiven System zum Backup-System.
Nachteil:
Höhere Netzauslastung, IDs für Nodes, Events und Alarme unterscheiden sich auf den Systemen.
Bei dieser Variante überwachen beide OpenNMS-Server aktiv, jedoch sendet nur ein Server Benachrichtigungen oder Forwarded Events/Alarme an ein Umbrella-System. Dies lässt sich über de Correlator (Drools Rules) realisieren.
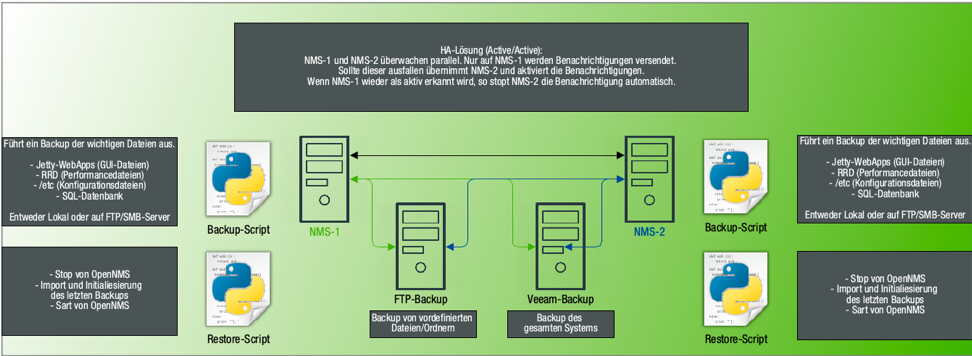
Active-Passive
Vorteil:
Keine zusätzliche Netzauslastung (mit Ausnahme der Synchronisation).
Auf beiden Systemen haben die Nodes die gleichen IDs.
Event und Alarm IDs sind auf beiden Systemen gleichn.
Nachteil:
Es dauert einige Minuten, bis OpenNMS gestartet ist. Damit geht auch ein höherer Datenverlust (Performancedaten) mit ein.
Bei dieser Variante überwacht ein OpenNMS-Server, während auf dem zweiten Server OpenNMS deaktiviert ist. Hier gibt es mehrere Möglichkeiten sicherzustellen, dass im Falle eines Ausfalls des aktiven OpenNMS Systems das passive System übernimmt.
Möglichkeit 1: Mittels eines proprietären Scriptes wird überwacht, ob OpenNMS auf dem produktiven System aktiv ist. Sollte dies nicht der Fall sein, startet das Script OpenNMS auf dem Backup-System. Für den Fall, dass auf dem produktiven System OpenNMS wieder aktiv wird, stoppt das Script OpenNMS auf dem Backup-System.
Um Downtimes und Datenverluste gering zu halten, kann man das System mit einigen Scripten erweitern, die automatisch Backups anlegen (lokal oder auf einem FTP-Server), Daten auf den Servern synchronisieren und im Fehlerfall das OpenNMS-System rasch wiederherstellen.
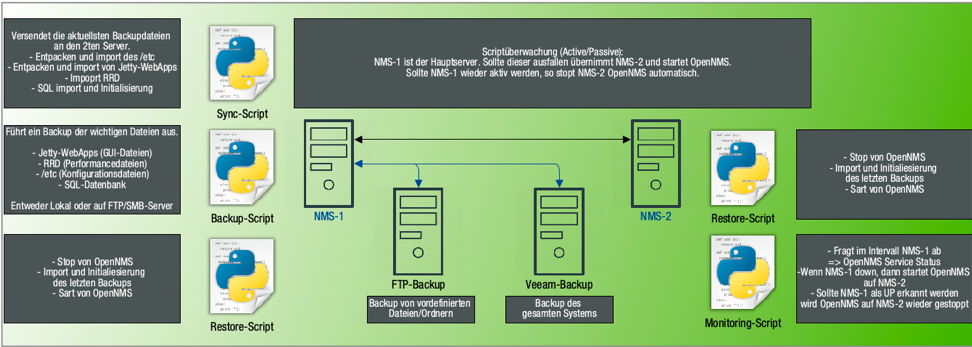
Möglichkeit 2: Eine Überwachung wird durch 3rd-Party Software wie mit einem Pacemaker Cluster realisiert. Diese Variante ist am schnellsten umzusetzen, hat jedoch den Nachteil, dass durch die zusätzliche Software im Problemfall eine weitere Fehlerquelle erzeugt wird.
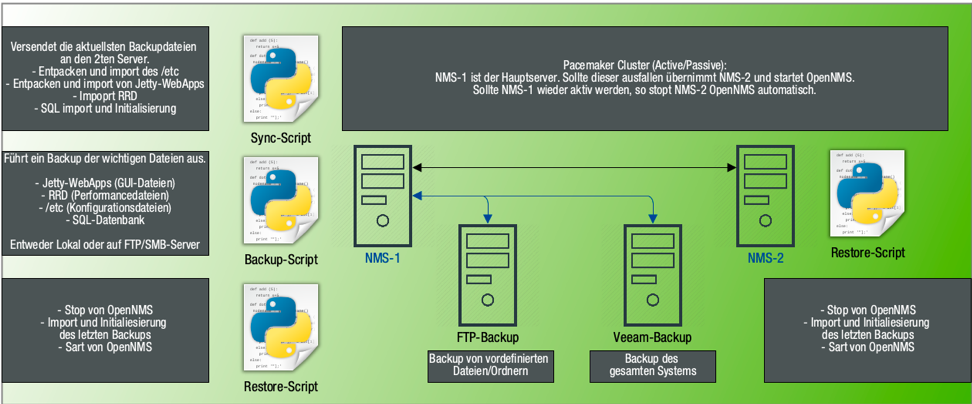
Praxisbeispiel: Pacemaker Cluster (Heartbeat, Corosync, Floating-IP)
Wie eine HA-Lösung mit Pacemaker eingerichtet werden kann wird nun hier an einem Beispiel beschrieben.
Angenommen werden haben zwei CentOS 7 Server mit OpenNMS:
IP von NMS-1 ist die 172.16.36.60
IP von NMS-2 ist die 172.16.36.61
Auf beiden Servern wurde in der /etc/hosts der folgende Eintrag geschrieben:
172.16.36.60 NMS-1
172.16.36.61 NMS-2
Auf beiden Servern wurde benötigte Software für die Umsetzung mit dem folgenden Befehl installiert:
yum install corosync pacemaker pcs -y
Auf beiden Servern wurde Pacemaker in den Autostart gesetzt und pcsd gestartet:
systemctl enable pacemaker corosync pcsd
systemctl start pcsd
Auf beiden Servern wurde das Passwort und der Usernames (hacluster) für das Cluster gesetzt:
passwd hacluster
Erstellen des Clusters (ab hier werden die Befehle nur auf dem NMS-1 ausgeführt):
Bei der Authentifizierung muss der Name vom vorherigen Punkt verwendet werden – also hacluster. Hier wird das dort vergebene Passwort verwendet.
pcs cluster auth NMS-1 NMS-2

pcs cluster setup –name NMS NMS-1 NMS-2
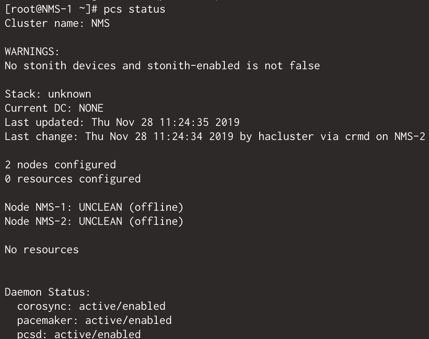
Hinzufügen des Clusters in den Autostart und Starten des Clusters:
pcs cluster enable NMS-1 NMS-2
pcs cluster start NMS-1 NMS-2
Die Funktion des Clusters wird überprüft:
pcs status
Weitere Konfigurationen von Pacemaker:
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
Hinzufügen der Ressourcen (Floating-IP und OpenNMS Service):
pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.16.36.70 cidr_netmask=32 op monitor interval=20s
pcs resource create OpenNMS system:opennms
Die Überprüfung der Ressourcen wird mit folgendem Befehl durchgeführt:
pcs status resources
Konfiguration, um beide Ressourcen auf dem gleichen Host laufen zu lassen:
pcs constraint colocation add OpenNMS vip INFINITY
pcs constraint order vip then OpenNMS
Konfiguration, um beide Ressourcen NMS-1 priorisieren zu lassen
pcs constraint location OpenNMS prefers NMS-1
pcs constraint location vip prefers NMS-1
Am Ende kann nochmal mit pcs status geprüft werden, ob das Cluster inkl. der Ressourcen funktioniert.
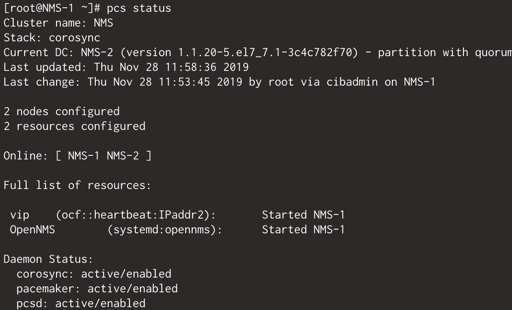
OpenNMS ist jetzt über die eigene IP und über die Floating-IP erreichbar:
(172.16.36.60(NMS-1) bzw. 172.16.36.61(NMS-2) + 172.16.36.70(Floating-IP))
Nun kann getestet werden, ob bei einem Ausfall von OpenNMS auf dem Server NMS-1 oder durch Ausfall des Servers NMS-1 das OpenNMS von Server NMS-2 gestartet wird und über die Floating-IP erreichbar ist. Der Test kann mit folgenden Befehlt durchgeführt werden:
pcs cluster stop NMS-1
Nach kurzer Zeit kann der Befehl pcs status auf dem NMS-2 ausgeführt werden. Hier sieht man, dass die Ressourcen nun auf NMS-2 liegen. Mit „service opennms -v status“ sollte zu sehen sein, dass OpenNMS gestartet ist bzw. noch startet.
Über die Floating-IP kann auch auf das Web-UI von Pacemaker zugegriffen werden: https://172.16.36.70:2224/manage
Die entsprechenden Zugangsdaten sind hacluster und das in der CLI vergebene Passwort. Hier kann man weitere Ressourcen oder auch Service Überwachungen hinzufügen und editieren.
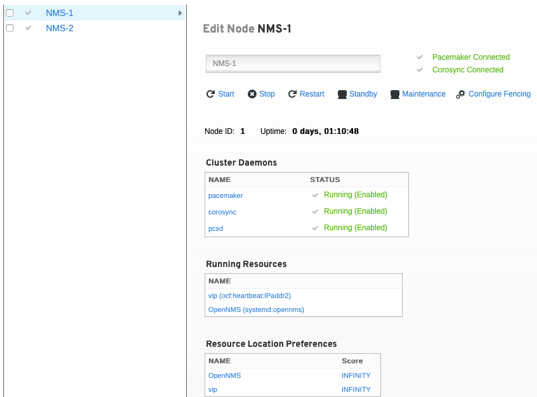
Konfiguration der Nodes
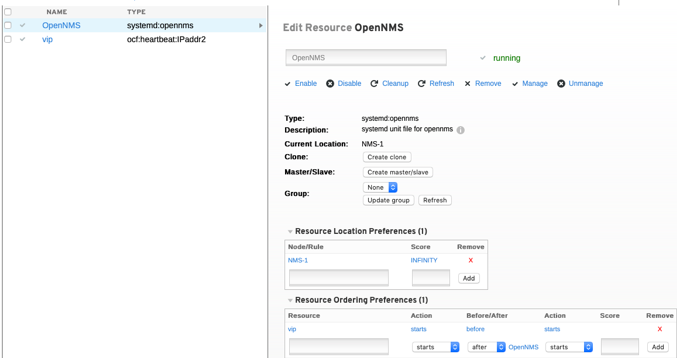
Konfiguration der Ressource OpenNMS (Überwachung des OpenNMS Dienstes)
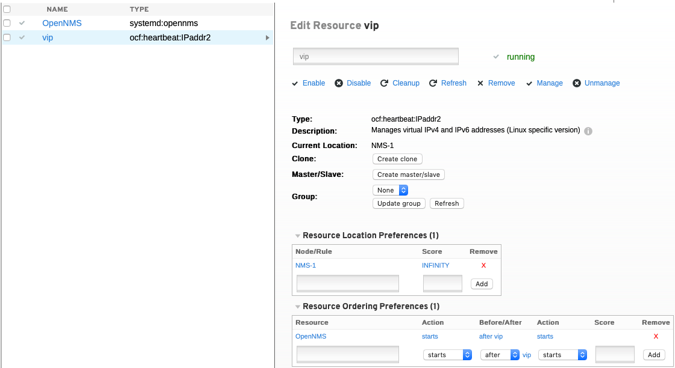
Konfiguration der Ressource Floating-IP (hier: vip [virtual ip])
Weitere Informationen rund um OpenNMS erhalten Sie von unserem erfahrenen Team. Sprechen Sie uns einfach an!
